GitHub is the leading platform for developers and companies worldwide to build and maintain their software. If you plan to collect data and crawl millions of repositories from GitHub, you'll need a powerful tool like Crawlbase to handle the task without interruptions. Our solution allows you to send unlimited requests with no bandwidth restrictions, supported by 99.99% network uptime. Designed for effortless API deployment and seamless integration, our tool simplifies your data collection process, making it efficient and reliable.
Easy to use, even with limited coding knowledge. Anyone can use it.
Highly scalable API using our worldwide proxies.
Automate browser scraping for JavaScript-heavy websites.
Protect Web Crawler from blocks, proxies, IP leaks, crashes, and CAPTCHAs.
Export data in various formats like CSV, Excel, and JSON.
Fetch fast, reliable, and high-quality data
All-in-one solution for collecting Github data
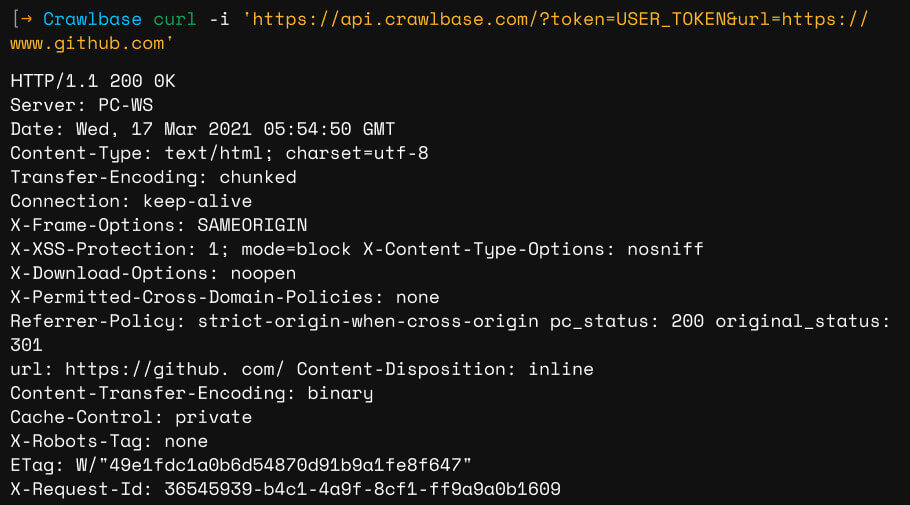
Use our Crawling API to get the full HTML code and scrape any content that you want. Send your crawled pages straight to the cloud using Crawlbase’s Cloud Storage. For huge projects, you can use the Crawler with asynchronous callbacks to save cost, retries, and bandwidth.
A Crawler can help you analyze the rising technologies and track their progress to spot new trends. With this data, you can decide which technologies to choose, enhance your skills, and allocate resources wisely.
Is scraping GitHub allowed?
GitHub's terms of service allow scraping for personal use but discourage it for commercial purposes without explicit permission. Additionally, you're not allowed to scrape GitHub for spamming purposes like sending unsolicited emails to users or selling personal information, such as to recruiters, headhunters, and job boards.
How to pull data from GitHub using Python?
Crawlbase is an effective tool to scrape millions of repositories from GitHub and is compatible with Python, Node.js, Ruby, and more. This GitHub Python scraper ensures smooth requests without blockages, offering unrestricted request volume with guaranteed bandwidth and an easily deployable API.
In what format Crawlbase scrapes GitHub data?
Crawlbase is designed to give users GitHub data in a structured format, mostly JSON, because it's simple and works well in web development. JSON organizes data with key-value pairs, making it easy to understand and analyze. To get detailed information about how the data is formatted, you can check Crawlbase's documentation or contact their support team.
How does a scraper work for GitHub?
The Crawlbase generic scraper works by using a set of predefined rules to get information from GitHub pages. It sends requests to GitHub, gets the web page's code, and then figures out the data. The scraper is smart and can move around GitHub's website to find important details like information about a repository. If you want to use the Crawlbase generic scraper, you can include it in your API requests. You just need to say "&scraper=generic-extractor" and give a coded GitHub link to specify what data you want to extract.
Are there any limitations or restrictions when using a scraper for GitHub?
When you're using web scraping tools, it's really important to follow the rules of the website you're scraping, like GitHub. Make sure to pay attention to things like how often you're making requests (rate limits), and think about what's fair and legal to do. It's all about being responsible and doing things the right way. If you want more info on the do's and don'ts, it's a good idea to check out Crawlbase's documentation or ask their support team for help.
Can I scrape data from private repositories on GitHub?
According to GitHub's terms of service, scraping data from private repositories is strictly prohibited without explicit authorization or permission from the repository owner.
How can I handle rate limiting or avoid being blocked while scraping GitHub?
To handle rate limiting or prevent being blocked when scraping GitHub, employ strategies like adjusting request rates, using proxies, optimizing API calls, and caching responses. Utilizing Crawlbase scraper can streamline these efforts, ensuring smoother data retrieval while complying with GitHub's guidelines.
What are the potential risks or challenges associated with GitHub scraping?
GitHub scraping comes with challenges like legal constraints, technical limitations (rate limiting and IP blocking), data accuracy, and ethical concerns. However, platforms like Crawlbase offer effective solutions, ensuring compliance with GitHub's policies and optimizing the scraping process to minimize risks and efficiently gather data within acceptable boundaries.
Is there customer support available for GitHub scraping services?
Yes, scraper services like Crawlbase often provide customer support. They offer assistance, guidance, and troubleshooting for users encountering issues or seeking help with the scraping process, API integration, or any service-related queries.
Start crawling the web today
Try it free. No credit card required. Instant set-up.