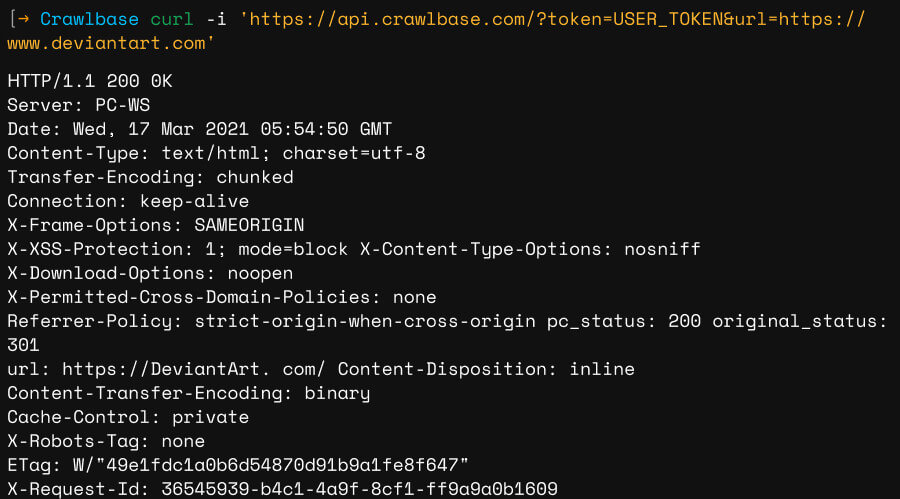
Crawlbase is where simplicity meets efficiency. It is accessible to all, needs minimal coding expertise, offers real-time, customized results and ensures protection against IP blocks, leaks, and CAPTCHAs. Crawl DeviantArt data to seek inspiration and collect creative data for your projects in HTML format easily.
Uninterrupted crawling with 99.9% uptime and high-quality servers
Crawlbase is powered by AI and machine learning for a top-notch proxy network, vigilantly managed by our expert engineers to ensure unwavering stability. Our API will allow you to extract as much content as you need from any DeviantArt gallery without file size restrictions. A single API call can download the data of an entire web page with a default rate limit of 20 requests per second (which can be increased if needed).
Easy to use, even with limited coding knowledge. Anyone can use it.
Highly scalable API using our worldwide proxies.
Automate browser scraping for JavaScript-heavy websites.
Protect Web Crawler from blocks, proxies, IP leaks, crashes, and CAPTCHAs.
Export data in HTML format.
Fetch fast, reliable, and high-quality data
All-in-one solution for collecting DeviantArt data
Use our Crawling API to get the full HTML code and scrape any content that you want. Send your crawled pages straight to the cloud using Crawlbase’s Cloud Storage. For huge projects, you can use the Crawler with asynchronous callbacks to save cost, retries, and bandwidth.
By default, our API can only crawl public data. However, we offer an option to send cookies if you require a login session to extract a website’s content. If you need more information, please see our product documentation or contact the support team.
What happens if my request fails?
We have a very high success rate in most cases, but in the event your request fails, you can simply retry the request as failed requests are not charged.
Do you have libraries for easy integration?
Yes, Crawlbase offers high scalability features for easy API integration to your existing system or infrastructure. We have libraries & SDKs for Node.js, PHP, Python, Ruby, and more.
Can I use a crawler for DeviantArt to download artworks?
It is not advisable to use a crawler to download artworks from DeviantArt, as it may breach terms of service and copyright regulations. However, if your intention is to gather public data for legitimate reasons, Crawlbase provides a solution. With AI-enhanced crawler and rotating proxies, Crawlbase guarantees a stable, efficient and legal scraping of public DeviantArt content.
In what format does Crawlbase deliver DeviantArt data?
Crawlbase provides DeviantArt data through its Crawling API in the form of complete HTML source code. This allows users to extract the raw HTML content of DeviantArt pages. Additionally, the Crawlbase Screenshots API captures high-resolution images of DeviantArt content.
How can I avoid IP blocks while using a crawler for DeviantArt?
To prevent getting blocked while using a crawler, it's important to use strategies that mimic human behavior. Crawlbase uses premium rotating proxies that change IP addresses dynamically. Additionally, their AI-enhanced crawler ensures a smooth and undetected experience.
Is it legal to scrape DeviantArt?
Scraping DeviantArt may violate terms of service and copyright laws, especially if you're collecting private or protected data. If scraping public data, ensure compliance with DeviantArt's policies to avoid legal issues.
Are there any limitations to DeviantArt Crawling?
DeviantArt crawling has limitations due to copyright policies and the platform's terms of service. Unauthorized crawling can lead to account suspension. Crawlbase helps mitigate these risks by offering an AI-enhanced crawler with rotating proxies to ensure legal and efficient public data extraction.
Start crawling the web today
Try it free. No credit card required. Instant set-up.