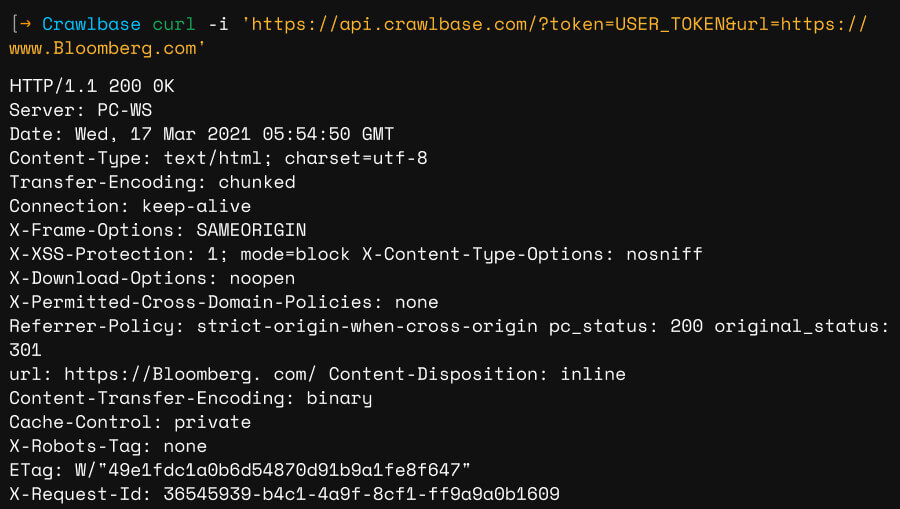
Extract Bloomberg public data securely within minutes with Crawlbase
With Crawlbase, you can scrape Bloomberg million of data within minutes. The scraped data can be obtained in HTML format, and you can use it for research or any other purpose. Our service provides unlimited bandwidth and you can instantly gain access to the most useful API features right off the bat. If you need any help in crawling or you get stuck anywhere our customer support can help you in any case so that you can extract valuable data effortlessly.
How Bloomberg data can help you grow your business
Bloomberg scraping for real-time stock prices, market trends, company details, economic indicators, and news articles has never been easier. Crawlbase is built on thousands of residential and data center proxies worldwide, combined with Artificial Intelligence, ensuring smooth and anonymous data extraction for easy analysis. These proxies help bypass CAPTCHAs and enhance protection against blocked requests. Make smart decisions and grow your business with Crawlbase.
Easy to use, even with limited coding knowledge. Anyone can use it.
Highly scalable API using our worldwide proxies.
Automate browser scraping for JavaScript-heavy websites.
Protect Web Crawler from blocks, proxies, IP leaks, crashes, and CAPTCHAs.
Export data in HTML format.
Fetch fast, reliable, and high-quality data
Frequently Asked Questions
Is it important to use proxies when crawling Bloomberg and why?
Using proxies when scraping Crawling is crucial for several reasons. Firstly, proxies help distribute requests across multiple IP addresses, reducing the risk of getting blocked by Bloomberg servers due to excessive traffic from a single IP. Secondly, proxies allow users to appear to be accessing Bloomberg from different geographic locations, enabling access to region-specific listings and preventing IP-based restrictions. Overall, proxies enhance anonymity, prevent bans, and enable more effective Bloomberg scraping.
Is it legal to scrape Bloomberg?
Yes, scraping Bloomberg is a legal gray area. Bloomberg’s terms of service prohibit web scraping, but the legality can vary by location and the purpose of scraping.
Can you scrape the Bloomberg terminal?
No, Crawlbase cannot scrape data directly from the Bloomberg Terminal. The Bloomberg Terminal operates within a closed ecosystem with stringent data access controls. It doesn't allow web scraping or API access from external sources. Users typically access Bloomberg data and analytics through the Bloomberg Terminal software, which provides a wide range of financial information and tools for analysis.
How do I collect Bloomberg data in Excel?
To collect Bloomberg data in Excel using Crawlbase, first, obtain an authentication token from Crawlbase's dashboard. Then, use Excel's Power Query feature to connect to Crawlbase's API, providing the necessary parameters such as the Bloomberg URL and any specific data you want to extract. Power Query will retrieve the data in HTML format, which you can then transform and load into Excel for analysis and visualization.
How do you ensure scraped data accuracy and reliability?
You should use reliable web crawlers to get reliable and accurate data. Crawlbase can provide near real-time data by making HTTP requests to Bloomberg’s live pages. The crawlers retrieves the latest available information, ensuring that the data is latest and reliable. However, the frequency of data updates also depend on the crawler's configuration and the user's requests.
What measures Crawlbase has in place to ensure data security and privacy?
Data security relies on how the crawler and the user handle it. A trusted service like Crawlbase takes care of data security by using secure communication methods like HTTPS. However, users need to use the extracted data responsibly and follow Indeed’s terms of service. This means respecting privacy laws and only gathering information that's already public.
What happens if my request fails?
Our crawling APIs and crawlers have a very high success rate. But if your request fails and does not go through, we won't charge you for those failed attempts. So, go ahead, you can retry with confidence.
Is it possible to have my API request geolocated from a specific country?
Yes, you can use the country parameter if you want your Bloomberg data extraction to be geolocated from a specific country. By default, your account will have access to more than 25 countries that you can use anytime on each of your API requests.
Start crawling the web today
Try it free. No credit card required. Instant set-up.
Start crawling in minutes
This website uses cookies...
We use cookies to make your experience better and show you content you’ll like. You’re in control - choose which cookies you want to allow here.
You can modify your preference later by clicking on the “Cookie Preferences” link at the bottom of the page.
Customize Cookies
Analytics Storage
Enables storage of information used to analyze website traffic and usage patterns.
Ad Personalization
Allows for the personalization of ads you see based on your interests and browsing behavior.
Ad User Data
Allows the sharing of your advertising-related data with Google.
Ad Storage
Enabled storage of information used for advertising purposes.